
Les chiffres de croissance sont impressionnants : selon les données du cabinet de conseil IDC [2], l’univers des données numériques doublera chaque année, pour atteindre 40 000 exaoctets en 2020. Et ce n’est qu’un début, car plus de 50 milliards d’objets connectés sont attendus d’ici 2020, donnant naissance à une nouvelle ère de la communication : l’Internet des objets (IoT).  Compte tenu de l’immense potentiel informationnel que recèle cet énorme volume de données, il n’est pas surprenant que le « big data » soit devenu l’une des principales tendances du secteur des TIC (Technologies de l’Information et de la Communication), suscitant de nombreuses controverses et débats quant à la manière d’exploiter les opportunités commerciales et les avantages concurrentiels qu’il représente, ainsi que les défis posés par la croissance exponentielle des données numériques et leur exploitation, aux niveaux technologique, réglementaire et même juridique.
Compte tenu de l’immense potentiel informationnel que recèle cet énorme volume de données, il n’est pas surprenant que le « big data » soit devenu l’une des principales tendances du secteur des TIC (Technologies de l’Information et de la Communication), suscitant de nombreuses controverses et débats quant à la manière d’exploiter les opportunités commerciales et les avantages concurrentiels qu’il représente, ainsi que les défis posés par la croissance exponentielle des données numériques et leur exploitation, aux niveaux technologique, réglementaire et même juridique.
Caractéristiques du Big Data : Le terme
« Big Data » (dont la traduction espagnole, bien que rarement utilisée, serait « grandes datos ») désigne les systèmes d’information et de communication qui traitent d’importants volumes de données. La définition établie par TechAmerica est la suivante [3] : « Le terme Big Data désigne de grands volumes de données variables, complexes et évoluant à grande vitesse ; leur capture, leur stockage, leur distribution, leur gestion et leur analyse nécessitent des technologies avancées. » Cette définition est volontairement subjective : par exemple, elle ne précise pas la taille des volumes de données (gigaoctets, téraoctets, pétaoctets, etc.). Ainsi, avec l’évolution des technologies, la quantité de données considérées comme du « Big Data » évolue également. De plus, cette taille dépend aussi du secteur concerné, car un ensemble de données relativement petit peut donner lieu à des combinaisons très complexes et variées. Par exemple, la corrélation des données de centaines de milliers de capteurs embarqués sur un avion constitue du « Big Data », car même si l’ensemble de données n’est pas volumineux, chaque capteur effectue des mesures à très grande vitesse, et celles-ci doivent être corrélées entre elles pour fournir des informations utiles.
Le terme « Big data » est souvent caractérisé par les quatre « V » bien connus [3] :
Le volume de données
désigne la quantité de données générées qui doivent être collectées, analysées et gérées pour la prise de décision. L'essor de la téléphonie mobile et des réseaux sociaux, conjugué à la multiplication des appareils connectés à Internet (smartphones, tablettes, capteurs, caméras IP, etc.), génère d'énormes quantités de données dont le volume ne cesse de croître selon la loi de Moore.
La vélocité
désigne la vitesse à laquelle les données sont produites ou modifiées. Pour améliorer les processus décisionnels, il est de plus en plus important que les données soient accessibles et analysées en temps réel. Cette augmentation de la vélocité est due à la multiplication des sources de données, à l'accroissement de la bande passante et à la puissance de calcul accrue des appareils qui les génèrent.
Diversité :
La croissance du volume d'informations provenant de nouvelles sources de données, internes et externes à l'organisation, représente un défi pour les services informatiques. Selon plusieurs études, seulement 15 % des informations actuelles sont structurées, c'est-à-dire facilement stockables dans des bases de données relationnelles ou des tableurs avec leurs lignes et colonnes traditionnelles. Autrement dit, 85 % des données sont non structurées (vidéos, audio, réseaux sociaux, blogs, messagerie instantanée, courriels, tweets, clics, données de capteurs, etc.), ce qui complexifie considérablement leur analyse avec les outils de veille stratégique classiques.
 Valeur :
Valeur :
La qualité des données peut être médiocre ou indéfinie en raison d’incohérences, d’ambiguïtés, de latence, etc. Les décisions relatives aux mégadonnées doivent reposer sur des données fiables, traçables et justifiables. De plus, il est important de considérer le potentiel d’interaction entre les données provenant de différentes sources, car des combinaisons aux résultats imprévisibles peuvent générer des informations très utiles.
Technologie du Big Data :
Les systèmes de gestion de bases de données (SGBD) traditionnels traitaient des informations structurées et relationnelles. Les outils traditionnels n’étaient pas conçus pour analyser des ensembles de données massifs et non structurés provenant de sources diverses, susceptibles de révéler des tendances cachées, des corrélations inconnues, etc.
Les systèmes de mégadonnées représentent l'évolution naturelle de ces systèmes, traitant des informations plus complexes répondant aux critères des 4 V (Valeur, Vulnérabilité, Vocalisation, Vulnérabilité ...
De toute évidence, cela implique l'adoption de nouvelles technologies. Ainsi, on observe le passage du SQL aux langages et outils basés sur MapReduce (initialement développé par Google) [4], tels que Hadoop, un environnement de programmation open source conçu par Yahoo et actuellement maintenu par Apache [hadoop.apache.org]. Des implémentations des bibliothèques MapReduce ont été écrites dans divers langages de programmation comme C++, Java et Python. De plus, au lieu d'un unique serveur haute performance, le Big Data utilise des architectures de clusters en anneau ou similaires, avec des serveurs standard moins performants fonctionnant de manière distribuée, dans le but de réduire les coûts et d'améliorer la disponibilité. Lors du traitement de données distribuées, ces technologies évitent de déplacer les données, ce qui serait très coûteux et lent. Au lieu de créer des sauvegardes, une série de répliques sont maintenues sur différents serveurs. Par conséquent, au lieu de traiter les données depuis un emplacement central, les programmes sont distribués sur les différents serveurs et exécutés en parallèle (map), les résultats étant ensuite consolidés (reduce).
Parmi les principaux fabricants d'applications « big data », on trouve : EMC, IBM, Oracle, SAP, Teradata, etc. Oracle se distingue notamment par sa capacité à proposer des solutions complètes : stockage, serveurs, machines virtuelles, systèmes d'exploitation, bases de données, intergiciels, applications, etc. ; qui peuvent être installées dans les centres de données du client, dans un cloud public ou privé, ou selon un modèle hybride.
Avantages du Big Data pour les opérateurs de télécommunications.
Les secteurs qui bénéficient actuellement le plus du Big Data sont les technologies de l'information et l'électronique, la finance, l'assurance et l'administration publique. Les grandes entreprises et organisations, notamment les entreprises du Web 2.0 (Amazon, Google, Facebook, LinkedIn, Twitter, etc.), ont été les premières à exploiter le Big Data pour réduire leurs coûts, améliorer leur productivité, optimiser le service client, développer de nouveaux produits et services, etc. [1]. Cependant, cette technologie est applicable à quasiment tous les secteurs et devient de plus en plus abordable pour les petites et moyennes entreprises (PME). Parallèlement à la croissance du Big Data, le marché de l'analyse prédictive a connu un essor considérable. Les entreprises comprennent l'opportunité d'utiliser le Big Data pour approfondir leur connaissance de leurs activités, de leurs concurrents et de leurs clients. Elles peuvent utiliser des modèles d'analyse prédictive pour réduire les risques, prendre de meilleures décisions et offrir des expériences client plus personnalisées [5].
Pour les opérateurs de télécommunications, le big data impliquera de nouveaux investissements, car il augmentera le trafic réseau et la demande en systèmes cloud. De nouvelles connaissances, plateformes matérielles, outils logiciels et processus opérationnels et commerciaux seront également nécessaires. Cependant, le big data est aussi une technologie puissante qu'ils peuvent exploiter pour gagner des parts de marché, améliorer l'image de marque, accroître leur chiffre d'affaires et leur rentabilité, et optimiser leurs opérations. Ainsi, le big data représente des défis importants pour les opérateurs, mais aussi une formidable opportunité.
Les opérateurs peuvent obtenir des informations précieuses sur leurs clients, de leur localisation à leurs centres d'intérêt, mais pour diverses raisons, ils n'ont pas encore pu exploiter pleinement le potentiel stratégique de ces données. Ces données sont structurées (profils clients, demandes de service, tarifs, incidents techniques, etc.), non structurées (documents, vidéos, images, contenu web, localisation, présence, DPI, signalisation SIP/Diameter/SS7, journaux, enregistrements des centres de contact, etc.) et partiellement structurées (profils clients enrichis d'enregistrements d'appels et d'informations externes telles que les blogs, les forums, les réseaux sociaux, etc.). Grâce à l'inspection approfondie des paquets (DPI), ils peuvent déterminer la bande passante consommée par l'utilisateur, ses heures de connexion, les sites web visités, les applications utilisées, etc. Ils pourraient même obtenir des informations supplémentaires en temps réel sur les goûts et les centres d'intérêt du client, bien que des contraintes juridiques relatives à la protection de la vie privée et à la confidentialité les en empêchent actuellement. Toutes ces informations, issues de sources diverses, doivent être organisées puis analysées afin d'éclairer la prise de décision.
Le cabinet de conseil Ovum confirme dans un rapport récent [6] le rôle de plus en plus important du big data dans le secteur des télécommunications. Cette technologie permet aux opérateurs, par exemple, de prévoir et de réduire le taux de désabonnement, de fidéliser leur clientèle grâce à des offres spéciales et/ou des forfaits, et de proposer des services personnalisés. Cependant, son déploiement doit encore être plus large si les opérateurs souhaitent monétiser leurs données clients. En effet, selon Ovum, l'un des principaux défis pour les opérateurs est de moderniser leur infrastructure informatique traditionnelle et de gagner en flexibilité, en s'inspirant du modèle de leurs concurrents OTT [7], capables de proposer rapidement de nouveaux services sans investissements importants.
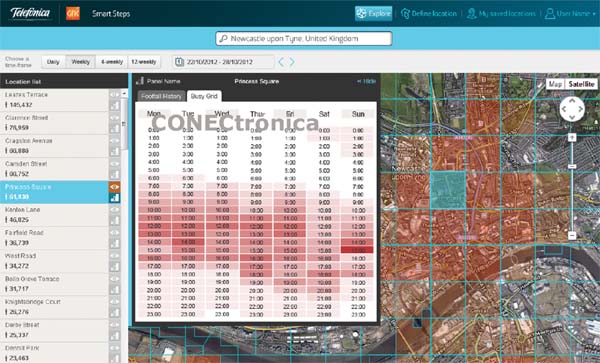
L'opérateur espagnol Telefónica figure toujours parmi les entreprises les plus visionnaires, comme en témoigne une nouvelle fois son approche du big data. En octobre 2012, Telefónica Digital a créé une nouvelle division internationale, Telefónica Dynamic Insights, afin de développer des offres commerciales pour les entreprises privées et les organismes publics, à partir des données massives du groupe Telefónica.
Le premier produit lancé au Royaume-Uni est « Smart Steps », qui exploite des données de réseau mobile agrégées et entièrement anonymisées. Ces données permettront aux entreprises privées et aux organismes publics de mesurer, comparer et comprendre les facteurs influençant la fréquentation d'un lieu donné à un moment précis. Ainsi, les entreprises pourront proposer des promotions ciblées et adaptées à chacun de leurs points de vente, et identifier les emplacements et les formats les plus pertinents pour l'ouverture de nouveaux magasins. « Smart Steps » aidera également les collectivités locales à évaluer l'impact de diverses initiatives sur la fréquentation, comme la réaction du public à la gratuité du stationnement dans différents quartiers ou le nombre de visiteurs lors de foires et de marchés. Telefónica Dynamic Insights développe également des produits analytiques pour des entreprises de nombreux secteurs, notamment la protection contre la fraude et les technologies des villes intelligentes, incluant la gestion du trafic.
Auteur:
Auteur: Ramón Jesús Millán Tejedor
Littérature
[1] « Le Big Data : la prochaine frontière de l’innovation, de la concurrence et de la productivité ». McKinsey Global Institute, McKinsey & Company, mai 2011.
http://www.mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation
[2] « Pour l’analyse des mégadonnées, il n’y a pas de limite à la taille. L’économie et la technologie convaincantes du calcul des mégadonnées. » Forsyth Communications, mars 2012.
http://www.cisco.com/en/US/solutions/ns340/ns517/ns224/big_data_wp.pdf
[3] « Démystifier le Big Data. Un guide pratique pour transformer le fonctionnement des administrations publiques. » TechAmerica Foundation
http://breakinggov.com/documents/demystifying-big-data-a-practical-guide-to-transforming-the-bus/
[4] « MapReduce : Traitement simplifié des données sur de grands clusters », Jeffrey Dean et Sanjay Ghemawat, Communications of the ACM - Numéro spécial 50e anniversaire 1958-2008, Volume 51, Numéro 1, janvier 2008.
http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/en//archive/mapreduce-osdi04.pdf
[5] « The Forrester Wave : Big Data Predictive Analytics Solutions ». Mike Gualtieri, Forrester, janvier 2013.
http://www.forrester.com/The+Forrester+Wave+Big+Data+Predictive+Analytics+Solutions+Q1+2013/fulltext/-/E-RES85601
[6] « L’analyse des mégadonnées et les télécommunications : comment les opérateurs télécoms peuvent monétiser les données clients ». Clare McCarthy et Shagun Bali, Ovum, mai 2013.
http://ovum.com/research/big-data-analytics-and-the-telco/
[7] « Over-The-Top vs Operators : la concurrence s'intensifie. » Ramón Millán, Dintel - Cadre supérieur n° III-1, Dintel, 2012.
http://www.ramonmillan.com/documentos/competenciaoperadoresvsott.pdf







