
Die Wachstumszahlen sind beeindruckend: Laut Daten des Beratungsunternehmens IDC [2] verdoppelt sich das digitale Datenvolumen jährlich und erreicht 2020 40.000 Exabyte. Und das ist erst der Anfang, denn bis 2020 werden voraussichtlich mehr als 50 Milliarden Geräte vernetzt sein, was eine neue Ära der Kommunikation einläutet: das Internet der Dinge (IoT).  Angesichts des enormen Informationspotenzials dieser riesigen Datenmenge ist es kein Wunder, dass „Big Data“ zu einem der wichtigsten Trends im IKT-Sektor (Informations- und Kommunikationstechnologien) geworden ist. Dies hat erhebliche Kontroversen und Diskussionen darüber ausgelöst, wie sich die damit verbundenen Geschäftschancen und Wettbewerbsvorteile nutzen lassen und welche Herausforderungen das exponentielle Wachstum digitaler Daten und deren Nutzung auf technologischer, regulatorischer und sogar rechtlicher Ebene mit sich bringen.
Angesichts des enormen Informationspotenzials dieser riesigen Datenmenge ist es kein Wunder, dass „Big Data“ zu einem der wichtigsten Trends im IKT-Sektor (Informations- und Kommunikationstechnologien) geworden ist. Dies hat erhebliche Kontroversen und Diskussionen darüber ausgelöst, wie sich die damit verbundenen Geschäftschancen und Wettbewerbsvorteile nutzen lassen und welche Herausforderungen das exponentielle Wachstum digitaler Daten und deren Nutzung auf technologischer, regulatorischer und sogar rechtlicher Ebene mit sich bringen.
Merkmale von Big Data:
„Big Data“ (spanisch: „grandes datos“, wenn auch selten verwendet) bezeichnet Informations- und Kommunikationssysteme, die große Datensätze verarbeiten. Die Definition von TechAmerica lautet [3]: „Big Data ist ein Begriff für große Datenmengen, die variabel, komplex und in hoher Geschwindigkeit verarbeitet werden und deren Erfassung, Speicherung, Verteilung, Verwaltung und Analyse fortschrittliche Technologien erfordern.“ Diese Definition ist bewusst subjektiv: Sie legt beispielsweise nicht fest, wie groß die Datenmengen sein müssen (Gigabytes, Terabytes, Petabytes usw.). Mit der Weiterentwicklung der Technologie ändert sich daher auch die Menge an Daten, die als „Big Data“ gelten. Darüber hinaus hängt die Größe auch vom jeweiligen Sektor ab, da bereits ein relativ kleiner Datensatz sehr komplexe und vielfältige Kombinationen hervorbringen kann. Beispielsweise ist die Korrelation von Hunderttausenden von Sensoren in einem Flugzeug „Big Data“, da zwar der Datensatz selbst nicht groß ist, aber jeder Sensor Messwerte in sehr hoher Geschwindigkeit liefert, die miteinander korreliert werden müssen, um verwertbare Informationen zu gewinnen.
„Big Data“ wird oft durch die bekannten vier „Vs“ [3] charakterisiert:
Das Datenvolumen
bezeichnet die Menge an generierten Daten, die erfasst, analysiert und verwaltet werden müssen, um Entscheidungen treffen zu können. Der Aufstieg der Mobiltelefonie und sozialer Netzwerke sowie die wachsende Anzahl internetfähiger Geräte (Smartphones, Tablets, Sensoren, IP-Kameras usw.) erzeugen enorme Datenmengen, die gemäß dem Mooreschen Gesetz stetig zunehmen.
Geschwindigkeit
bezeichnet die Rate, mit der Daten erzeugt oder verändert werden. Für bessere Entscheidungsprozesse ist es zunehmend wichtig, dass Daten in Echtzeit verfügbar sind und analysiert werden können. Die steigende Geschwindigkeit ist auf die Zunahme von Datenquellen, die höhere Bandbreite der Verbindungen und die gestiegene Rechenleistung der datenerzeugenden Geräte zurückzuführen.
Vielfalt:
Die zunehmende Informationsflut aus neuen Datenquellen innerhalb und außerhalb des Unternehmens stellt IT-Abteilungen vor große Herausforderungen. Laut mehreren Studien sind nur 15 % der aktuellen Informationen strukturiert, d. h. sie lassen sich problemlos in relationalen Datenbanken oder Tabellenkalkulationen mit ihren traditionellen Zeilen und Spalten speichern. Anders ausgedrückt: 85 % sind unstrukturiert (Videos, Audio, soziale Medien, Blogs, Chats, E-Mails, Tweets, Klicks, Sensordaten usw.), was die Auswertung mit herkömmlichen Business-Intelligence-Tools erheblich erschwert.
 Wert:
Wert:
Die Datenqualität kann aufgrund von Inkonsistenzen, Mehrdeutigkeiten, Latenzzeiten usw. mangelhaft oder undefiniert sein. Entscheidungen im Bereich Big Data müssen auf zuverlässigen, nachvollziehbaren und begründeten Daten basieren. Darüber hinaus ist es wichtig, das Potenzial für Wechselwirkungen zwischen Daten aus verschiedenen Quellen zu berücksichtigen, da Kombinationen mit unvorhersehbaren Ergebnissen sehr nützliche Informationen liefern können.
Big-Data-Technologie:
Traditionelle Datenbankmanagementsysteme (DBMS) arbeiteten mit strukturierten und relationalen Informationen. Herkömmliche Werkzeuge waren nicht dafür ausgelegt, massive, unstrukturierte Datensätze aus verschiedenen Quellen zu analysieren, die verborgene Muster, unbekannte Zusammenhänge usw. aufdecken können.
Big-Data-Systeme stellen die natürliche Weiterentwicklung dieser Systeme dar und verarbeiten komplexere Informationen, die den vier Kriterien V (Verantwortlichkeit, Genauigkeit, Transparenz) entsprechen. Programmierumgebungen für Big Data zeichnen sich durch ihre Leistungsfähigkeit in der statistischen und grafischen Analyse aus. Ausgefeilte automatisierte Simulationsalgorithmen unterstützen menschliche Entscheidungen und verbessern so den Entscheidungsprozess, reduzieren Risiken und ermöglichen die Gewinnung wertvoller Erkenntnisse, die sonst verborgen blieben. Mithilfe von Big Data lassen sich unzählige „Was-wäre-wenn“-Simulationsszenarien testen, die ein breites Spektrum an demografischen, zeitlichen, geografischen und anderen Daten berücksichtigen, die sich in Echtzeit an Veränderungen anpassen können.
Dies erfordert die Einführung neuer Technologien. So erfolgte der Wechsel von SQL zu Sprachen und Werkzeugen, die auf MapReduce (ursprünglich von Google) [4] basieren, wie beispielsweise Hadoop, einer Open-Source-Programmierumgebung, die von Yahoo entwickelt und aktuell von Apache [hadoop.apache.org] unterstützt wird. MapReduce-Bibliotheken wurden in verschiedenen Programmiersprachen wie C++, Java und Python implementiert. Anstelle eines einzelnen Hochleistungsservers nutzt Big Data Ringcluster-Architekturen oder ähnliche Architekturen mit weniger leistungsstarken Standardservern, die verteilt arbeiten, um Kosten zu senken und die Verfügbarkeit zu verbessern. Bei der Verarbeitung verteilter Daten werden die Daten nicht verschoben, was sehr kostspielig und zeitaufwendig wäre. Statt Backups zu erstellen, werden Replikate auf verschiedenen Servern verwaltet. Anstatt die Daten zentral zu verarbeiten, werden die Programme auf die verschiedenen Server verteilt und parallel ausgeführt (Map), wobei die Ergebnisse anschließend zusammengeführt werden (Reduce).
Zu den führenden Herstellern von Big-Data-Anwendungen gehören: EMC, IBM, Oracle, SAP, Teradata usw. Insbesondere Oracle zeichnet sich durch seine Fähigkeit aus, Komplettlösungen anzubieten: Speicher, Server, virtuelle Maschinen, Betriebssysteme, Datenbanken, Middleware, Anwendungen usw., die in den eigenen Rechenzentren des Kunden, in einer öffentlichen oder privaten Cloud oder nach einem Hybridmodell installiert werden können.
Vorteile von Big Data für Telekommunikationsanbieter:
Die Branchen, die derzeit am meisten von Big Data profitieren, sind Informationstechnologie und Elektronik, Finanzen, Versicherungen und die öffentliche Verwaltung. Große Unternehmen und Organisationen, insbesondere Web-2.0-Unternehmen (Amazon, Google, Facebook, LinkedIn, Twitter usw.), nutzten Big Data als erste, um Kosten zu senken, die Produktivität zu steigern, den Kundenservice zu verbessern, neue Produkte und Dienstleistungen zu entwickeln usw. [1]. Die Technologie ist jedoch in nahezu jeder Branche anwendbar und wird zunehmend auch für kleine und mittlere Unternehmen (KMU) erschwinglich. Parallel zum Wachstum von Big Data hat der Markt für prädiktive Analysen einen Boom erlebt. Unternehmen erkennen das Potenzial von Big Data, um ihr Wissen über ihr Geschäft, ihre Wettbewerber und ihre Kunden zu erweitern. Mithilfe prädiktiver Analysemodelle können Unternehmen Risiken minimieren, bessere Entscheidungen treffen und personalisierte Kundenerlebnisse bieten [5].
Für Telekommunikationsanbieter bedeutet Big Data neue Investitionen, da der Netzwerkverkehr und die Nachfrage nach Cloud-Systemen steigen werden. Neue Kenntnisse, Hardwareplattformen, Softwaretools sowie operative und kommerzielle Prozesse werden ebenfalls notwendig. Gleichzeitig ist Big Data aber auch eine leistungsstarke Technologie, die Anbieter nutzen können, um Marktanteile zu gewinnen, die Kundenzufriedenheit zu steigern, Umsatz und Rentabilität zu erhöhen und ihre Abläufe zu optimieren. Big Data stellt die Anbieter somit vor große Herausforderungen, bietet ihnen aber auch enorme Chancen.
Betreiber können wertvolle Informationen über ihre Kunden gewinnen, vom Standort bis hin zu persönlichen Interessen. Aus verschiedenen Gründen konnten sie den strategischen Wert dieser Daten jedoch bisher nicht vollständig ausschöpfen. Die Daten sind strukturiert (Kundenprofile, Serviceanfragen, Preise, technische Störungen usw.), unstrukturiert (Dokumente, Videos, Bilder, Webinhalte, Standort, Anwesenheit, DPI, SIP/Diameter/SS7-Signalisierung, Protokolle, Aufzeichnungen von Kontaktzentren usw.) und teilstrukturiert (Kundenprofile angereichert mit CDRs oder Anrufdatensätzen und externen Informationen wie Blogs, Foren, sozialen Medien usw.). Mithilfe von DPI (Deep Packet Inspection) können sie ermitteln, wie viel Bandbreite der Nutzer verbraucht, wann er sich verbindet, welche Websites er besucht, welche Anwendungen er nutzt usw. Sie könnten sogar zusätzliche Echtzeitinformationen über die Vorlieben und Interessen des Kunden erhalten, sind aber derzeit durch rechtliche Bestimmungen zum Datenschutz und zur Vertraulichkeit eingeschränkt. All diese aus verschiedenen Quellen gewonnenen Informationen müssen organisiert und anschließend analysiert werden, um die Entscheidungsfindung zu unterstützen.
Das Beratungsunternehmen Ovum bestätigt in einem aktuellen Bericht [6] die zunehmende Bedeutung von Big Data im Telekommunikationssektor. Diese Technologie ermöglicht es Betreibern beispielsweise, Kundenabwanderung vorherzusagen und zu reduzieren, die Kundenbindung durch Sonderangebote und/oder Produktpakete zu stärken und personalisierte Dienste anzubieten. Allerdings muss diese Technologie noch breiter eingesetzt werden, wenn Betreiber ihre Kundendaten monetarisieren wollen. Laut Ovum besteht eine der größten Herausforderungen für Betreiber darin, ihre traditionelle IT-Infrastruktur zu modernisieren und flexibler zu werden, indem sie dem Modell ihrer OTT-Konkurrenten [7] nacheifern, die neue Dienste schnell und ohne große Investitionen anbieten können.
Der spanische Telekommunikationsanbieter Telefónica zählt seit jeher zu den fortschrittlichsten Unternehmen – ein Fakt, den er mit seinem Umgang mit Big Data einmal mehr unter Beweis stellt. Im Oktober 2012 gründete Telefónica Digital die neue globale Geschäftseinheit Telefónica Dynamic Insights, um auf Basis der Big Data der Telefónica-Gruppe kommerzielle Angebote für private Unternehmen und öffentliche Organisationen zu entwickeln.
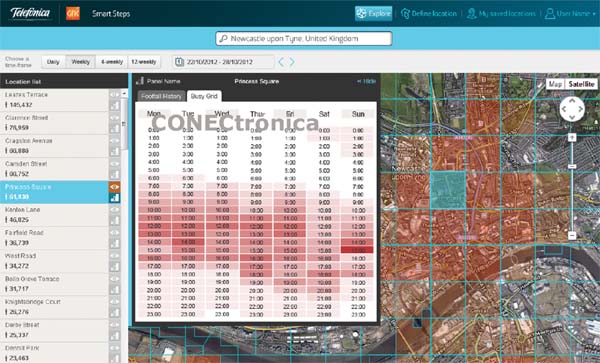
Das erste Produkt, das speziell in Großbritannien eingeführt wird, ist „Smart Steps“. Es nutzt aggregierte und vollständig anonymisierte Mobilfunknetzdaten. Mithilfe dieser Daten können private Unternehmen und öffentliche Einrichtungen messen, vergleichen und analysieren, welche Faktoren die Besucherzahlen an einem bestimmten Ort zu einem bestimmten Zeitpunkt beeinflussen. So können Unternehmen gezielte, auf ihre Filialen zugeschnittene Werbeaktionen anbieten und die besten Standorte und geeignetsten Formate für neue Filialen ermitteln. „Smart Steps“ unterstützt außerdem Kommunen bei der Bewertung der Auswirkungen verschiedener Initiativen auf die Besucherfrequenz, beispielsweise die Resonanz der Öffentlichkeit auf kostenlose Parkplätze in verschiedenen Stadtteilen oder die Besucherzahlen von Messen und Märkten. Telefónica Dynamic Insights entwickelt darüber hinaus Analyseprodukte für Unternehmen verschiedenster Branchen, darunter Betrugsprävention und Smart-City-Technologien, einschließlich Verkehrsmanagement.
Autor:
Autor: Ramón Jesús Millán Tejedor
Literatur
[1] „Big Data: Die nächste Grenze für Innovation, Wettbewerb und Produktivität“. McKinsey Global Institute, McKinsey & Company, Mai 2011.
http://www.mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation
[2] „Für Big-Data-Analysen gibt es kein ‚zu groß‘. Die überzeugende Ökonomie und Technologie des Big-Data-Computing.“ Forsyth Communications, März 2012.
http://www.cisco.com/en/US/solutions/ns340/ns517/ns224/big_data_wp.pdf
[3] „Big Data verständlich gemacht. Ein praktischer Leitfaden zur Transformation der Regierungsarbeit.“ TechAmerica Foundation
http://breakinggov.com/documents/demystifying-big-data-a-practical-guide-to-transforming-the-bus/
[4] „MapReduce: Vereinfachte Datenverarbeitung auf großen Clustern“, Jeffrey Dean und Sanjay Ghemawat, Communications of the ACM – Jubiläumsausgabe zum 50-jährigen Bestehen (1958–2008), Band 51, Ausgabe 1, Januar 2008.
http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/en//archive/mapreduce-osdi04.pdf
[5] „The Forrester Wave: Big Data Predictive Analytics Solutions.“ Mike Gualtieri, Forrester, Januar 2013.
http://www.forrester.com/The+Forrester+Wave+Big+Data+Predictive+Analytics+Solutions+Q1+2013/fulltext/-/E-RES85601
[6] „Big-Data-Analysen und die Telekommunikationsbranche: Wie Telekommunikationsunternehmen Kundendaten monetarisieren können.“ Clare McCarthy und Shagun Bali, Ovum, Mai 2013.
http://ovum.com/research/big-data-analytics-and-the-telco/
[7] „Over-The-Top vs. Betreiber: Der Wettbewerb verschärft sich.“ Ramón Millán, Dintel – Senior Management Nr. III-1, Dintel, 2012.
http://www.ramonmillan.com/documentos/competenciaoperadoresvsott.pdf



